Database Indexing
When developing a web application for sales analysis, I encountered a significant challenge: sluggish query performance. It left me pondering how major companies effortlessly deliver data within seconds, even when dealing with billions of records. As I delved deeper, I realized that implementing optimizations like database indexing could be the key to speeding up operations.
To grasp the effectiveness of indexing, it's crucial to understand some fundamentals:
Storage of Table Data: Before diving into indexing, it's essential to comprehend how databases store table data, i.e., rows.
Types of Indexing: There are various types of indexing mechanisms available, each suited to different use cases. Understanding them helps in choosing the right one for the job.
Data Structure and Indexing: Indexing relies on specific data structures and algorithms. Understanding these structures sheds light on how indexing operates under the hood.
By combining this knowledge, we can gain insights into how Database Management Systems (DBMS) optimize performance through indexing. Let's explore these concepts further to uncover how indexing revolutionizes data retrieval speed.
How table data (rows) are actually stored?
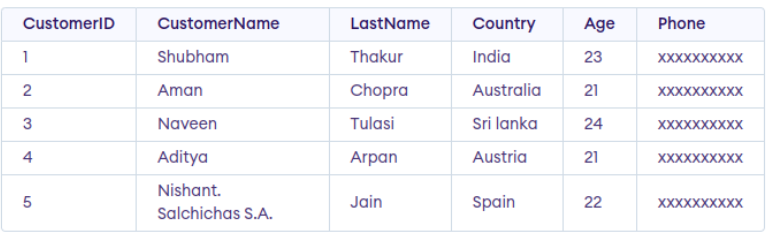
This is just a logical representation of data. Actual data is not stored in this way.
In DBMS, actual data is stored in data pages.
Data pages typically have a size of 8KB, although this can vary depending on the specific database system.
These data pages serve as the basic unit for storing and retrieving information within the database.
Each data page can hold multiple rows of data, organized in a format optimized for efficient storage and retrieval.
Understanding how data is organized within these pages is crucial for optimizing database performance and query efficiency.
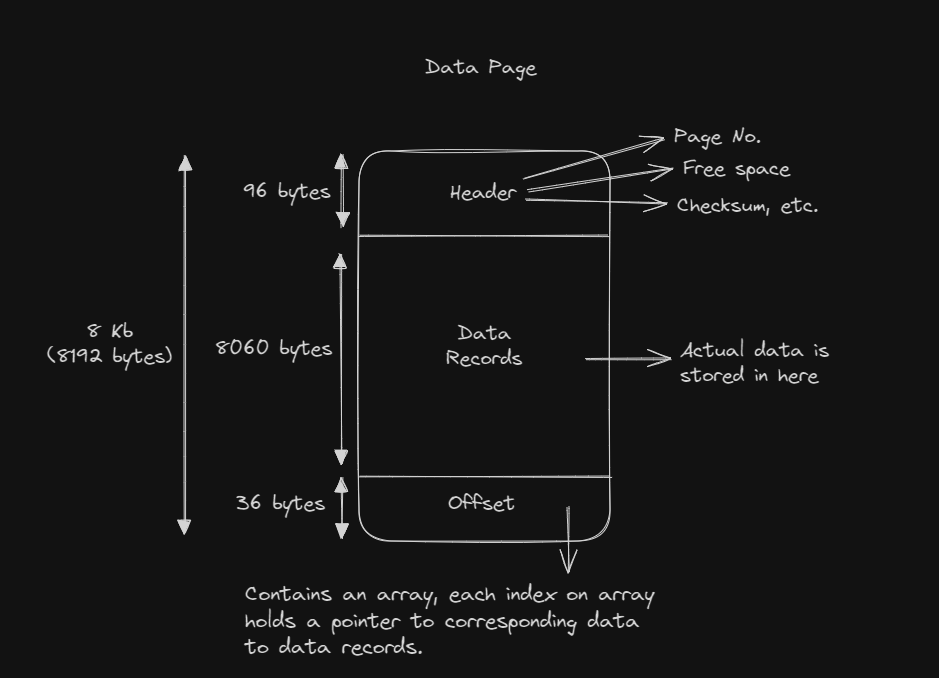
So lets say if 1 table row is 64 bytes. 1 data page can have ~125 DB rows
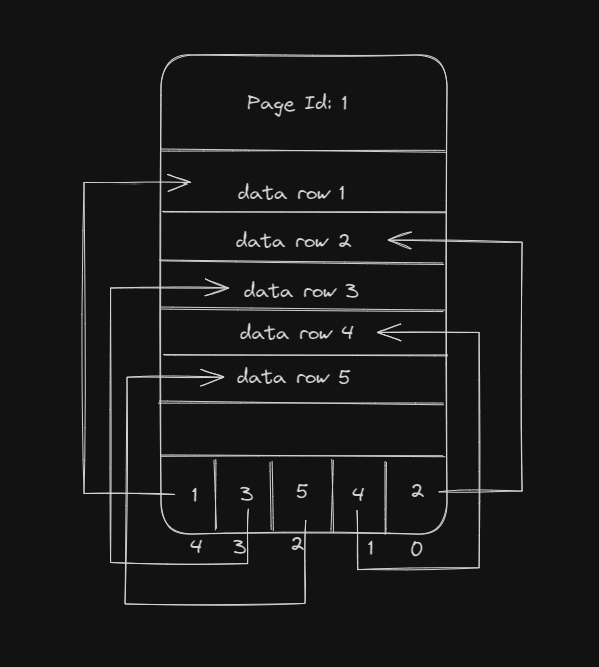
DBMS creates and manage these data pages. As for storing 1 table data, it create many data pages.
These data pages ultimately gets stored in the Data Block in physical memory like disk.
What is Data block?
The minimum amount of data that can undergo a read or write operation in computer storage systems.
Managed by the underlying storage system, such as a disk.
Data Block Size:
Typically ranges from 4KB to 32KB, with 8KB being a common size.
Smaller block sizes offer more efficient storage utilization.
Larger block sizes can improve performance for larger files or sequential access patterns.
Composition:
Multiple data blocks can be grouped together to form larger units.
Larger units include data pages or clusters.
Storage Efficiency:
Small block sizes are useful for storing small files or a large number of files efficiently.
Larger block sizes may be preferable for larger files or specific performance requirements.
Considerations:
The choice of block size depends on factors like the specific use case and performance requirements.
File systems or database management systems may utilize data blocks differently based on their needs and optimizations.
DBMS maintains the mapping of Data Page and Data Block.
| Data Page 1 | Data Block 1 |
| Data Page 2 | Data Block 1 |
| Data Page 3 | Data Block 2 |
| Data Page 4 | Data Block 2 |
DBMS controls Data pages like what row goes in which page or sequence of page. But it has no control over Data Blocks it can be scattered over the disk.
What type of indexing present in RDBMS?
There are two types of indexing present in RDBMS:
Clustered Indexing
Non - Clustered Indexing
Before we understand this we need to understand what is indexing and what data structure it uses.
What is Indexing?
Indexing is a fundamental technique in database management systems that enhances the efficiency of data retrieval by organizing and sorting data based on specified criteria. Without indexing, DBMS has to iterate each and every table row to find the requested Data.
i.e O(N), if there are millions of rows, query can take some time to fetch the data.
Which Data Structure provides better time complexity then O(n)?
B+ Tree, it provides O(log N) time complexity for insertion, searching & deletion.
How B-tree works?
A B-tree is a balanced tree data structure used for storing and managing sorted data efficiently. Here's a concise overview of how it works:
Node Structure: Each node contains a fixed number of keys and pointers.
Insertion: New keys are inserted by traversing the tree to find the appropriate position and splitting nodes if necessary to maintain balance.
Deletion: Keys are removed by adjusting the tree structure and balancing nodes as needed.
Search: Operations like insertion, deletion, and search follow a similar process of tree traversal based on key comparison.
Balancing: B-trees automatically balance themselves during insertion and deletion to maintain optimal performance.
Performance: B-trees offer efficient 𝑂(log 𝑛) time complexity for insertion, deletion, and search operations, making them suitable for large datasets in databases and file systems.
Uniform Leaf Level: In a B-tree, all leaf nodes are at the same level, ensuring balanced access time for all elements.
Order 𝑀: An 𝑀- order B-tree means each node can have at most 𝑀 children, and thus 𝑀−1 keys per node.
There are 2 order, 3 order, 4 order, 5 order B-trees.
Here's a brief overview:
2-order B-tree: Also known as a binary search tree, each node can have at most 2 children. In a 2-order B-tree, each node typically contains one key and two children.
3-order B-tree: Each node can have at most 3 children. In a 3-order B-tree, each node can have up to 2 keys and 3 children.
4-order B-tree: Each node can have at most 4 children. In a 4-order B-tree, each node can have up to 3 keys and 4 children.
5-order B-tree: Each node can have at most 5 children. In a 5-order B-tree, each node can have up to 4 keys and 5 children.
let's visualize the insertion process for a 3-order B-tree
[7, 2, 9, 11, 15, 5, 37]
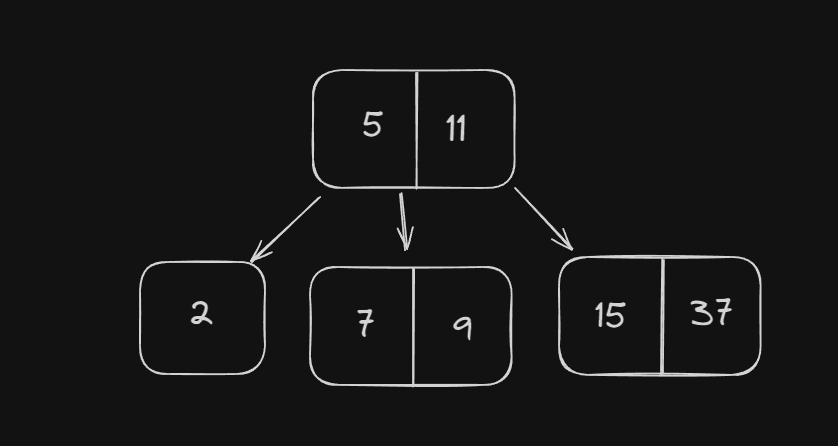
B+ Tree
B+ tree is exactly same as B tree, with additional feature like child nides are also linked to each other.
DBMS uses B+ Tree to manage its Data pages and Rows within the pages.
Root node or Intermediary node hold the value which is used for faster searching the data. Possible that value might have deleted from DB, but its can be used for sorting the tree.
Leaf node actually holds the indexed column value.
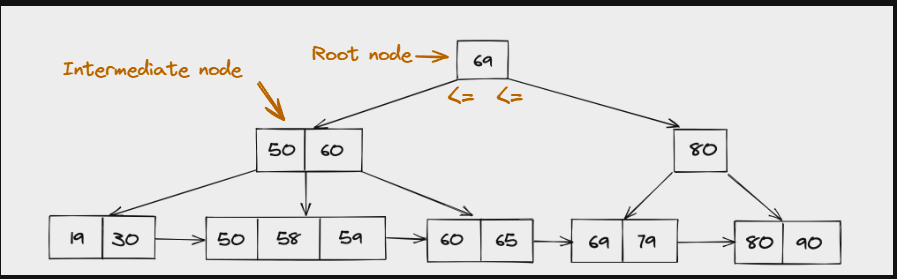
Clustered Indexing
Clustered indexing is a method in database systems that physically organizes table data on disk according to the values of one or more indexed columns. The primary key is often used as the default clustered index if one is not explicitly defined. It enables efficient data retrieval by storing rows in sorted order based on the index key(s), resulting in faster access, especially for range queries. However, updates to clustered index columns may impact performance due to the need for data reorganization. Choosing the appropriate columns for a clustered index is crucial for optimizing data retrieval efficiency.
Non - Clustered Indexing
Single Clustered Index per Table: A table typically supports only one clustered index. This index determines the physical arrangement of data within the table.
Default Clustered Index: If no clustered index is explicitly specified, the database management system (DBMS) often defaults to using the primary key, provided it meets the criteria of being unique and non-null, as the clustered index.
Fallback Mechanism for Missing Primary Key: In the absence of a primary key, some DBMSs automatically generate a hidden column that serves as a unique identifier for each row. This hidden column is designed to ensure uniqueness and non-nullability, typically incrementing sequentially. It functions as the clustered index to facilitate efficient data retrieval and storage organization.
End Note:
Indexing is a powerful technique that significantly enhances the performance of data retrieval operations in database systems. By organizing data efficiently and leveraging advanced data structures like B+ trees, indexing reduces query response times, enabling web applications to deliver insights rapidly even with large datasets. Understanding the nuances of indexing and its impact on database performance is essential for building scalable and responsive applications in today's data-driven world.